
 赤羽(Akabane)
赤羽(Akabane)
目次
因果関係を特定するメンデルランダム化試験とは?
でその手法というのが「メンデルランダム化試験」なる研究デザインなんですが、一言で言うなら遺伝子レベルで被験者を分けて実験する方法のこと。例えばこんな研究テーマがあったとします。
- たばこは早死にリスクを高める!
そしてこのテーマについて調べていくのに、手っ取り早くできたのが観察研究。簡単なイメージだと、
- アメリカ国民50000人分のデータを集めて
- 過去の喫煙歴と早死にのリスクとの関係を調べた
- 早死にリスクはヘビースモーカーと非喫煙者で比べた
みたいな感じ。要は既存のデータを使って「ヘビースモーカーほど早死にのリスクが高かった!」みたいな相関関係を見つけていく手法ですね。
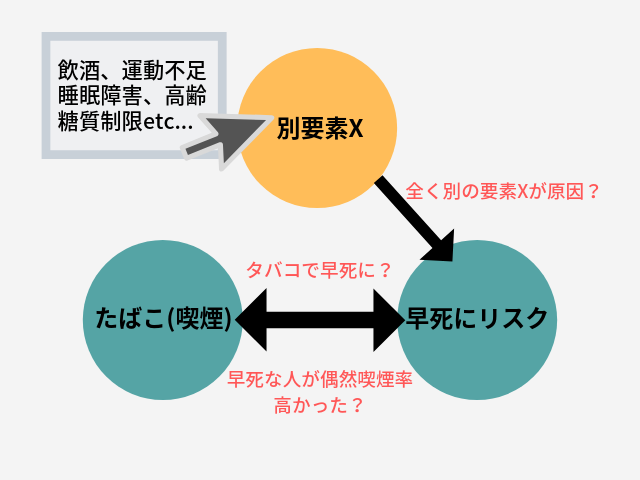
ただしこの手法では大きな問題がありまして、それは因果関係がどうしてもわからないという点。
※筆者が作成。
つまり、たばこが病気を引き起こして早死に繋がったのか、それとも病気のストレスとかで逆にたばこを吸う傾向があっただけなのか、はたまた全く関係ない要素Xのせいなのか?みたいに結果に対する原因がハッキリしないんですね。これが従来の観察研究の課題でありました。
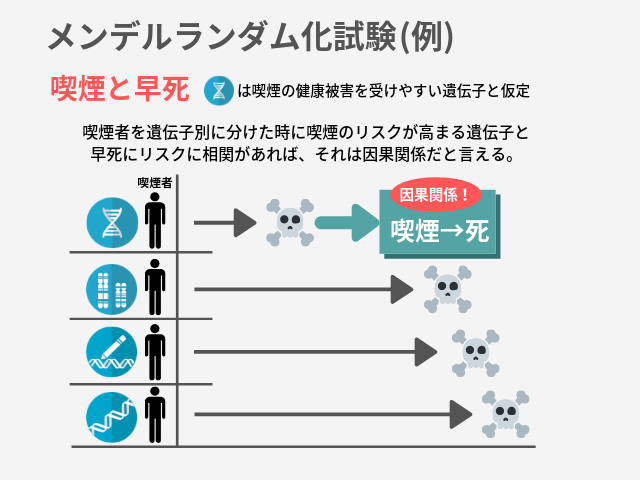
そしてそこへメンデルランダム化試験の登場。この手法では対象者を遺伝子レベルで調べて、結果に関係がありそうな遺伝子別にグループ分けを行います。
※筆者が作成。
図の例だと、一番上の遺伝子は「たばこの悪影響を受けやすくなる遺伝子」だと仮定しております。そして結果を見てみると、どうやらこの遺伝子を持っている喫煙者は早死にのリスクが高い、と。この結果から、
- たばこが早死にリスクを高めている!
ということがはじめて言えるようになります。たばこと関わりが深い遺伝子を持つ対象者で早死にリスクが高かったということは、たばこが早死に関係していると考えるのが妥当ですからね。
ではここまででメンデルランダム化試験についてザックリまとめると、
- 遺伝子レベルで対象者をグループ分けする研究手法
- 従来の観察研究では難しかった因果関係の特定に有効
こんな感じになりますが、最後にランダム化比較試験と比べた時のメリットを紹介して締めくくりです。
最高級の研究デザイン「ランダム化比較試験」と「メンデルランダム化試験」
まずランダム化比較試験(RCT)とは何ぞや?という部分について。詳しくは過去に紹介しておりますが、
- AとBグループ(場合によってはC,Dと続くことも)間で何かの効果を比べて結果の差を確認する研究方法
ザっとこんな手法。例えば「キットヨクナール」というサプリがあったとして、これが風邪の治療に効果があるか?を調べたいとしたら、
- 風邪を引いている100名の患者を対象に
- ランダムに2つのグループに分けて2週間過ごしてもらう
- 実験終了までの風邪の治り具合を比べる
・キットヨクナールグループ..毎日キットヨクナールを毎日1錠服用する(50名)
・プラセボ(偽薬)グループ..なんの効果もないサプリを毎日1錠服用する(50名)
こんなデザインになります。これでキットヨクナールグループのほうが風邪の完治率が高かった!みたいになれば、やはりこれも因果関係である可能性が高いと言えるんですね。(他にグループ間で違いがないから)
そしてこのRCTこそが統計的に最強の研究デザインだと言われておりまして、研究の信頼性を確かめる時も出来ればRCTの研究を優先的に探したほうが良さげ。
とここで「なら全部RCTで確かめればいいじゃない?」という疑問が生まれますが、もちろん短所もありまして、
- 実験費用が高い
- 厳重な管理のもと行われるため長期で行うのが難しい
- その分集められるサンプル数(対象者数)も少なくなってしまう
この辺りが課題みたい。そもそもお金がかかるからそんなに乱発はできないし、観察研究と違って対象者を厳しい管理の下ずっと追っていかないといけないし、その分人数が多いと大変だからできても数百人くらいが限度だったり。だから先ほど出た「早死にリスク」みたいに、何十年という長期で見ないとちゃんとしたデータが得られないテーマだとRCTは不向き。
そして、ここでメンデルランダム化試験の出番。こちらの手法ならばRCTの短所を上手くカバーできまして、
- 実験費用を安く抑えられる
- 対象者を管理しなくても観察研究のデータから遺伝子を調べるだけでOK
- その分集められるサンプル数も増やせる
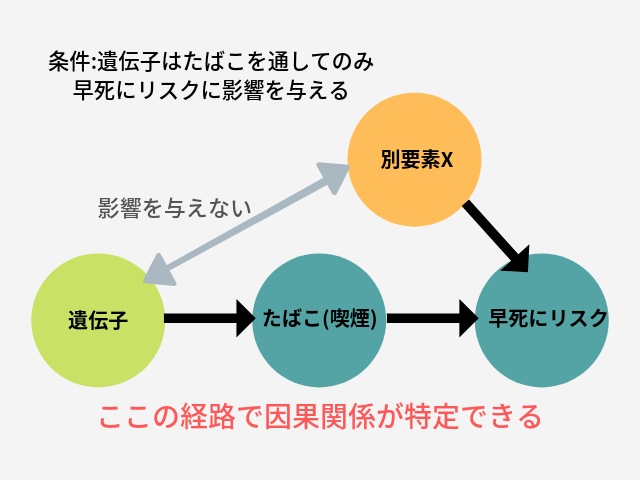
この3つは全面カバーできます。ということで「結局メンデルランダム化が最強か」と片付いてしまいそうですが、こちらも大きな問題点があります。それは、実験で使用する遺伝子が別要素に影響する場合は使い物にならないという点。改めてメンデルランダム化のデザインを見ていくと、
※筆者が作成。
こんな感じで成り立っているんですね。つまり前提として、操作する遺伝子がリスク因子(たばこ)にのみ影響を与えるものだ、という条件が成り立っていないといけない、と。
※筆者が作成。
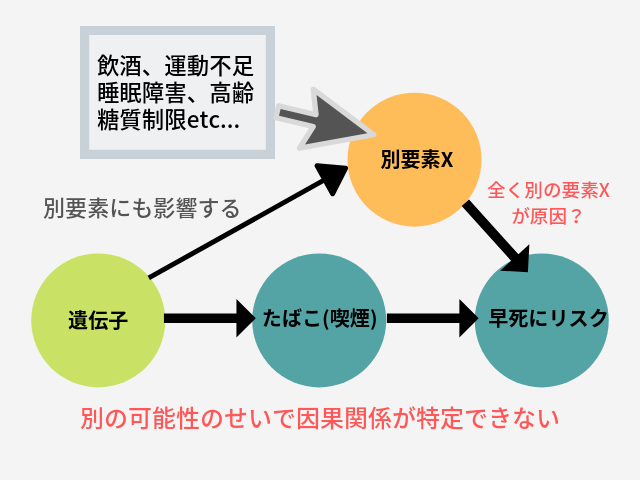
しかし遺伝子が全く別要素にも影響していたとしたら?当然「遺伝子→たばこ→早死に」以外の可能性も出てくるので、この場合因果関係は説明できません。このように遺伝子が複数の要素に影響することを「多面発現」と呼ぶそうです。
赤羽(Akabane)
関連記事はこちらをどうぞ
 因果関係をハッキリさせる研究法「ランダム化比較試験(RCT)」とは?【データ分析の基礎】
因果関係をハッキリさせる研究法「ランダム化比較試験(RCT)」とは?【データ分析の基礎】  肥満と炎症の根深い関係 -遺伝子レベルで因果関係が特定された件-
肥満と炎症の根深い関係 -遺伝子レベルで因果関係が特定された件-

